有些场景下,需要隔离不同的DB,彼此DB之间不能互相访问,但实际的业务场景又需要从A DB访问B DB的情形,这时怎么办?我认为有如下常规的三种方案:
1.双方提供RESET API,需要访问不同DB数据时,可以通过API来获取指定数据;
这种方案优点是隔离性、定制性强,统一出入口,只能通过指定的API访问指定的数据;缺点与优点是对立的,也就是定制性太强,导致每次业务发生变更,需要访问不同数据的时候,需要双方更改API的入参或返参,降低了开发效率;而且无法使用表JOIN,这样在某些情况下也会导致查询数据效率变低。目前主流的方案都是建议使用API方案
2.利用DB的同步技术(如:SQL SERVER的订阅复制、MYSQL的主从复制脚本等)来实现不同DB的数据同步共享
这种方案优点是可以在同一个DB访问到另一个DB中所需表的数据,可以直接JOIN,把原来的跨DB访问变成了同一个DB的事情;缺点是依赖DB的同步技术,而且两台DB服务器的网络必需互通,没有完全的隔离,且往往同步过来的表不允许直接修改,或需修改仍然需要跨DB修改或使用方案1的API来进行修改。
3.通过程序代码实现两个DB的数据同步(增、删、改、查),如:可以定时轮询源DB的A表,然后获取变更的记录(一般是:增、删、改的记录),再通过程序代码把源DB的A表的变更记录批量更新(若是新增、则是插入,若是修改,则是更新,若是删除,则是删除)到目的DB的A表中。
这种方案的优点是:可以根据实际情况灵活定制同步的表数据,不局限于某一张表或某一个DB,可以保证不同DB间同步表的数据一致性,让本来跨DB操作表变成了同一个DB的事情,而且可以增、删、改、查,功能不受限;缺点是灵活性太强,程序代码实现可靠的跨DB的实时同步逻辑的实现复杂度较高,对于开发人员的要求较高,如果写的同步逻辑无法保证实时、可靠、高可用,那对于业务来讲是灾难性的。
上述三种方案,第1、2方案基本都是定制化的常规方案,我(梦在旅途,)今天要分享的是第3种方案:跨DB增量(增、改)同步两张表的数据,注意是增量同步,其中删除这个我没有说明,原因是如果DB表中记录是物理删除(即:真实的DELETE),那就无法简单的通过程序代码获取到删除的记录,除非在DB中加入DELETE触发器记录删除记录的主键到临时表或开启更改追踪(CHANGE_TRACKING)或DB日志分析,故本文讲的是不给表、DB增加额外负担的情况实时增量同步,至于删的同步这个我认为最好是逻辑标记删除(过期最后清理【真实删除】),而不要物理删除。
关于程序代码实现跨DB同步表数据方案,之前已有总结过,详见: ---》4.利用BCP(sqlbulkcopy)来实现两个不同数据库之间进行数据差异传输(即:数据同步)
之前的文章同步主要是基于TranFlag标记字段 或触发器来实现同步,这种方式必需对表数据的增、删、改逻辑都有要求与规范,也就是增、改必需更改TranFlag=0,删必需记录表删除临进表中,这样才能实现同步逻辑,而今天是在这个同步基础上(BCP),不给表、DB增加额外负担的情况实时增量同步,对数据源的插入、改动没有要求。
代码如下:(以下同步适用于SQL SERVER 不同DB的表增量同步)
try { SqlConnection obConnSrc = new SqlConnection(connLMSStr); SqlConnection obConnDest = new SqlConnection(mconnCCSStr); string lastTamp = ClsDatabase.gGetFieldValue(obConnSrc, "update TS_SyncUptime set UPTime=GETDATE() OUTPUT (deleted.LastUPstamp) as oldtamp FROM TS_CCSUptime WHERE TableName=N'tableNameA'", "oldtamp"); string selectSql = @"SELECT id,aaa,bbb,ccc,ddd,eee,fff FROM tableNameA WHERE 其它同步过滤查询条件 AND CONVERT(bigint,sys_tamp)>{0}"; selectSql = string.Format(selectSql, lastTamp); master.TransferBulkCopy(selectSql, obConnSrc, "tableNameA", obConnDest, (stable) => { var colMaps = new Dictionary (); foreach (DataColumn col in stable.Columns) { colMaps.Add(col.ColumnName, col.ColumnName); } return colMaps; }, (tempTableName, stable, destConn, srcConn) => { StringBuilder saveSqlBuilder = new StringBuilder("begin tran" + Environment.NewLine); string IUSql = master.BuildInsertOrUpdateToDestTableSql("tableNameA", tempTableName, new[] { "id" }, stable.ExtendedProperties[master.MapDestColNames_String], 2); saveSqlBuilder.Append(IUSql); saveSqlBuilder.AppendLine("commit"); ClsDatabase.gExecCommand(destConn, saveSqlBuilder.ToString()); ClsDatabase.gExecCommand(srcConn, "update TS_SyncUptime set UPTime=GETDATE(),LastUPstamp=CONVERT(bigint,sys_tamp) FROM TS_SyncUptime WHERE TableName=N'tableNameA'"); return false; }); } catch (Exception ex) { writeLog(ex);//记错误日志 } 上述同步代码逻辑很简单,可以参照之前的文章,这里主要是说明几个重要点:
1.TS_SyncUptime表用于记录与管理同步任务的信息,主要包含如下几个字段:
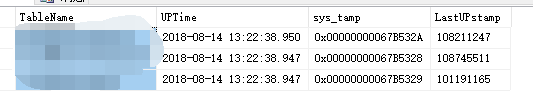
TableName:要同步的表名,UPTime每一次同步的触发时间点(可更改),sys_tamp行变更时间戳(不可更改),LastUPstamp行最后有效变量时间戳(可以更新)
2.具体关键同步逻辑如下:
2.1先更新TS_SyncUptime表,以便触发sys_tamp行变更时间戳发生改变(相当于记录同步触发时间点),在更改的同时取出LastUPstamp行最后有效变更时间戳(相当于上次同步的触发时间点)
2.2使用LastUPstamp作为过滤条件,查询>源DB的源表中时间戳字段,这样就可以查询出自上一次同步触发点到当前时间待同步的记录(增、改)
2.3利作BCP执行同步(详见之前文章说明)
2.4确保同步成功后,再次更新TS_SyncUptime表,并把sys_tamp行变更时间戳(当前触发时间点)更新到LastUPstamp行最后有效变量时间戳(记住本次触发时间点)
如上步骤即可实现可靠的同步,有人可能有疑问,这样就能实现可靠同步吗?我这里解释一下:
3.1同步触发时记录当前触发时间点,并取得上一次的触发时间点(这里的上一次触发时间点是指上一次开始准备同步的记录时间点,确保从上一次查询到同步完成之间的时间点都包括其中,防止漏数据)
3.2如果同步的任一环节失败(只要最终没有同步成功),那么再次同步触发时均取到的是同 一个时间点(LastUPstamp),而且即使重复执行同步逻辑,也不会出现重复(因为存在则更新不存在则插入原则),保证幂等,这样就确保了同步的可靠性
3.3当然如果某个时间点的数据或某个DB有问题,导致一直同不不成功,可能会出现一直同步不过去的情况,这种情况可以加上预警+人工干预,这个是概率的事情。
好了,如果大家有什么好的意见或建议欢迎下方留言评论,谢谢!